建索引
logstash建索引
- 去json数据生成网站生成的json格式的数据
生成的数据不能直接使用,需要手动加工一下,我已经加工好了,可以点击下载数据 - 通过logstash导入json数据到Elasticsearch,参考我的博文Elasticsearch5.6.9-logstash读取json格式文件数据导入到Elasticsearch
使用_bulk api 建立索引
- 去官网下载数据accounts.json
curl -O https://raw.githubusercontent.com/elastic/elasticsearch/master/docs/src/test/resources/accounts.json - 命令行建索引
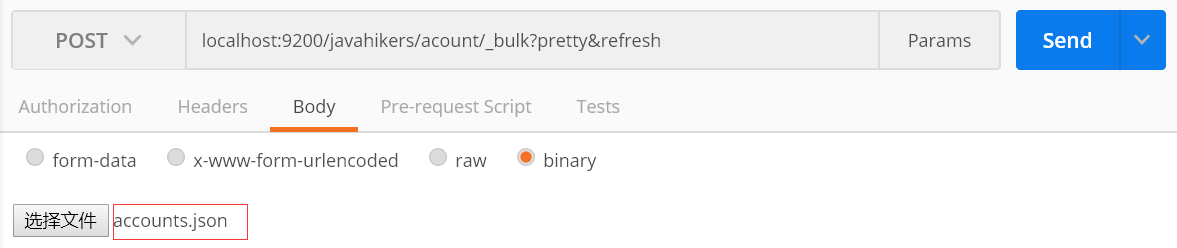
curl -H 'Content-Type: application/json' -XPOST 'localhost:9200/javahikers/acount/_bulk?pretty&refresh' --data-binary '@accounts.json' - 或者postman工具建索引
列出所有索引
GET请求postman http://localhost:9200/_cat/indices?v
GET请求kibana GET /_cat/indices?v,可以省略前面的ip和端口,默认连接本地9200端口,后面介绍都将通过kibana给es发送请求
health status index uuid pri rep docs.count docs.deleted store.size pri.store.size
green open javahikers OToEZOxvSbWJVtlEpGVOGg 5 1 1000 0 1.2mb 664.8kb
green open logstashjsontest 7UZWLq26QTyDdVW2QczuyA 5 1 12 0 164.8kb 82.4kb
简单查询
GET请求 GET javahikers/acount/400
条件查询
POST请求 POST javahikers/_search
下面统一通过 REST request body发送查询参数
match_all
查询所有,from起始数据下标,数据下标是从0开始。size返回数据条数。
不写from和size默认返回前10条数据
POST javahikers/_search
{
"query": {
"match_all": {}
},
"from": 0,
"size": 1
}
返回结果,根据字段名可以知道其含义
took单位毫秒,hits返回的数据
{
"took": 8,
"timed_out": false,
"_shards": {
"total": 5,
"successful": 5,
"skipped": 0,
"failed": 0
},
"hits": {
"total": 1000,
"max_score": 1,
"hits": [
{
"_index": "javahikers",
"_type": "acount",
"_id": "25",
"_score": 1,
"_source": {
"account_number": 25,
"balance": 40540,
"firstname": "Virginia",
"lastname": "Ayala",
"age": 39,
"gender": "F",
"address": "171 Putnam Avenue",
"employer": "Filodyne",
"email": "virginiaayala@filodyne.com",
"city": "Nicholson",
"state": "PA"
}
}
]
}
}
match
带有sort时,查询结果里面_score字段会变成null
POST javahikers/_search
{
"query": {
"match": {
"address": "Avenue"
}
},
"sort": [
{
"age": {
"order": "desc"
}
}
]
}
聚合查询
aggs->terms
POST javahikers/_search
{
"aggs": {
"group_by_account_number": {
"terms": {
"field": "age"
}
},
"group_by_balance": {
"terms": {
"field": "balance"
}
}
}
}
group_by_account_number的查询结果里面,可以看出默认获取排名前10的分组数数据,
这些分组数据数量+doc_count_error_upper_bound+sum_other_doc_count等于全部文档数量
"doc_count_error_upper_bound": 0,
"sum_other_doc_count": 463,
aggs->stats
POST javahikers/_search
{
"aggs": {
"age_count": {
"stats": {
"field": "age"
}
}
}
}
查询结果里面,包含了age的最小值,最大值,平均值和总和的计算
"aggregations": {
"age_count": {
"count": 1000,
"min": 20,
"max": 40,
"avg": 30.171,
"sum": 30171
}
}

